Validating documents in bulk
Since you have only three document schema types, it’s not that hard to get a sense of what’s going on from looking through the documents. Most projects with some maturity might have a lot of schema types and a lot of content. This is where it becomes useful to use the Sanity CLI to investigate mismatches between your content and the schema that is supposed to describe it.
# in apps/studionpx sanity@latest documents validateThe CLI will give you a small warning about potential pitfalls with this command, if you want to skip this warning in the future, you can run the following:
# in apps/studionpx sanity@latest documents validate -yWhen the command has run, you may have a list of warnings or errors about missing field values:
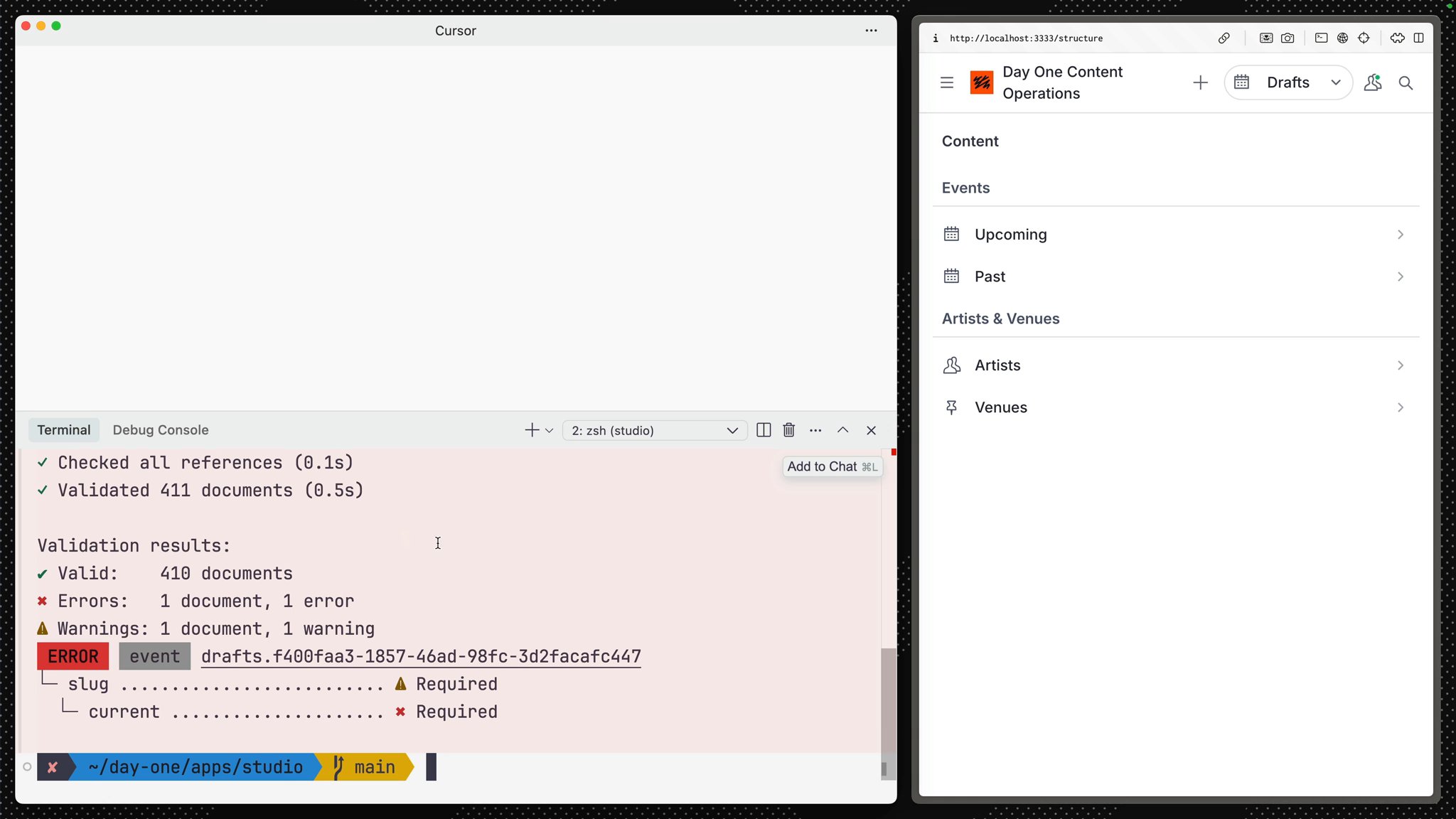
Validation results:✔ Valid: 408 documents✖ Errors: 2 documents, 2 errors⚠ Warnings: 2 documents, 2 warnings ERROR event 57c1561e-378c-4124-9aa2-88c0db96a037└─ slug .......................... ⚠ Required └─ current ..................... ✖ Required
ERROR event drafts.57c1561e-378c-4124-9aa2-88c0db96a037└─ slug .......................... ⚠ Required └─ current ..................... ✖ RequiredThis means there is content in your dataset which is not aligned with the validation rules in your Studio schema. In the instance of our error above, there's one document that doesn't have a slug field value.
If you had validation errors, and have now fixed them, re-run:
# in apps/studionpx sanity@latest documents validate -yAnd you should see output like:
Validation results:✔ Valid: 408 documents✖ Errors: 0 documents, 0 errors⚠ Warnings: 0 documents, 0 warningsGreat! You now have a dataset full of valid content and the skills to ensure validation in bulk as part of future content operations.
You are now ready to do the opposite, namely, changing the schema and updating the content accordingly.